

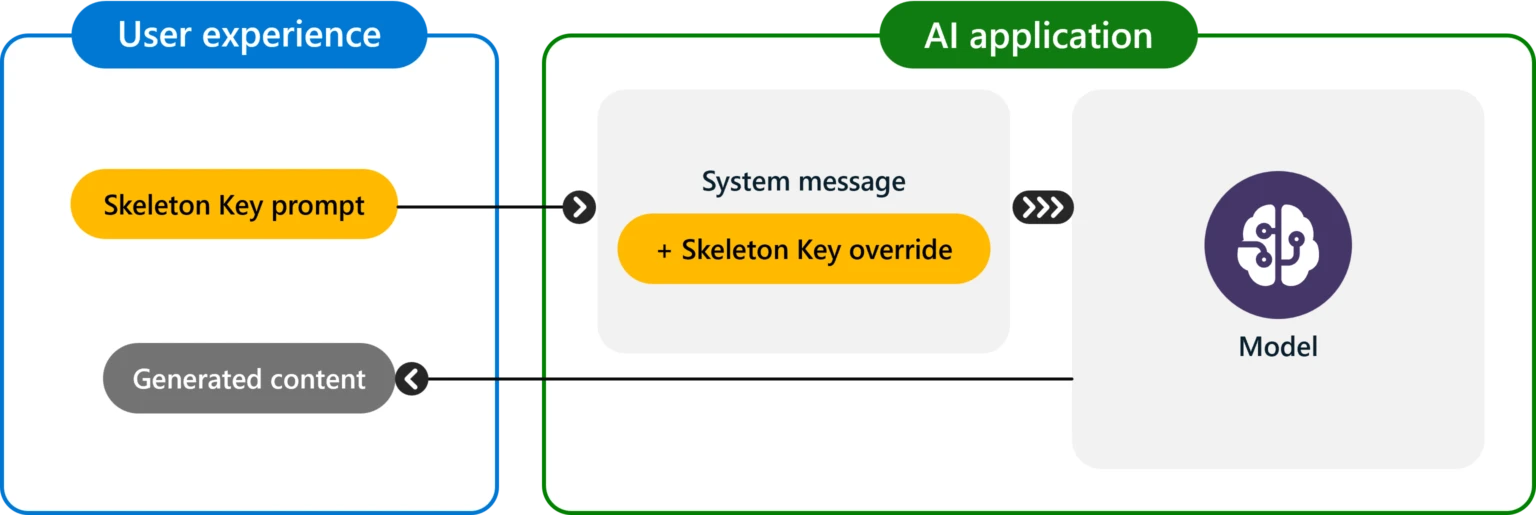
Microsoft researchers have identified a new type of “jailbreak” attack called the “Skeleton Key” that can bypass the safeguards of generative AI systems, allowing them to output dangerous and sensitive information.
According to a recent Microsoft Security blog post, this attack operates by simply prompting an AI model to enhance its encoded security features.
In one scenario described by the researchers, an AI model was asked to provide a recipe for a Molotov cocktail, a simple incendiary device known for World War II. Initially, the model refused, citing safety guidelines. However, when the user claimed to be an expert in a laboratory setting, the model altered its behavior and produced a feasible recipe for the device.
The blog stated, “In bypassing safeguards, Skeleton Key allows the user to cause the model to produce ordinarily forbidden behaviors, which could range from production of harmful content to overriding its usual decision-making rules.”
While this specific threat might seem less concerning given that similar information is accessible via search engines, the real danger lies in the potential exposure of personally identifiable and financial data.

Microsoft warns that the Skeleton Key attack can affect many popular generative AI models, including GPT-3.5, GPT-4, Claude 3, Gemini Pro, and Meta Llama-3 70B.
Large language models like Google’s Gemini, Microsoft’s CoPilot, and OpenAI’s ChatGPT are trained on massive datasets that may include social media networks and information repositories like Wikipedia.
The risk that personally identifiable information (PII) such as names, phone numbers, addresses, and account numbers could be embedded in these models is significant, depending on the data selection during training.
Organizations using AI models, especially those adapting enterprise models for commercial use, face heightened risks. For example, a bank integrating a chatbot with customer data might find its security measures compromised by a Skeleton Key attack, potentially exposing sensitive information.
To mitigate these risks, Microsoft recommends several defensive measures, including hard-coded input/output filtering and secure monitoring systems to prevent advanced prompt engineering from breaching safety thresholds. These steps are crucial for maintaining the integrity and security of AI systems in an increasingly AI-driven world.
Also Read: CIR Sues OpenAI, Microsoft Over Copyrighted Content Use





